Data Engineering.
Unlock Business Value with Powerful, Scalable, and Flexible Data Engineering and Data Management Solutions.
Data volumes and velocities are increasing exponentially, driven by new unstructured and semi-structured data types that legacy data warehouses and workflows have trouble handling. Start capturing the value of all your data – and making better business decisions – with CapeStart’s end-to-end data engineering and management solutions.
Compete and Win with a Single Source of Truth Across the Enterprise.
Your organization has a lot of structured and unstructured data – from Internet of Things (IoT) device and sensor data, to clickstream, multimedia, and other data types. But you can’t extract maximum value from all that raw data without modern data engineering and management processes.
CapeStart’s data engineering services across the data and analytics value chain enable the seamless ingestion and integration of all your data, convert it to actionable information, and allow data-driven decision making based on an integrated and well-governed single source of truth across the entire enterprise.
- How social media is an early indicator of upcoming serious ADRs.
- Blending human effort with AI technology to solve this problem.
- Our quality and ability to involve experts such as MDs for case reviews
- Team well-versed in media monitoring and pharmacovigilance.
- Flexibility to present reports in various formats.
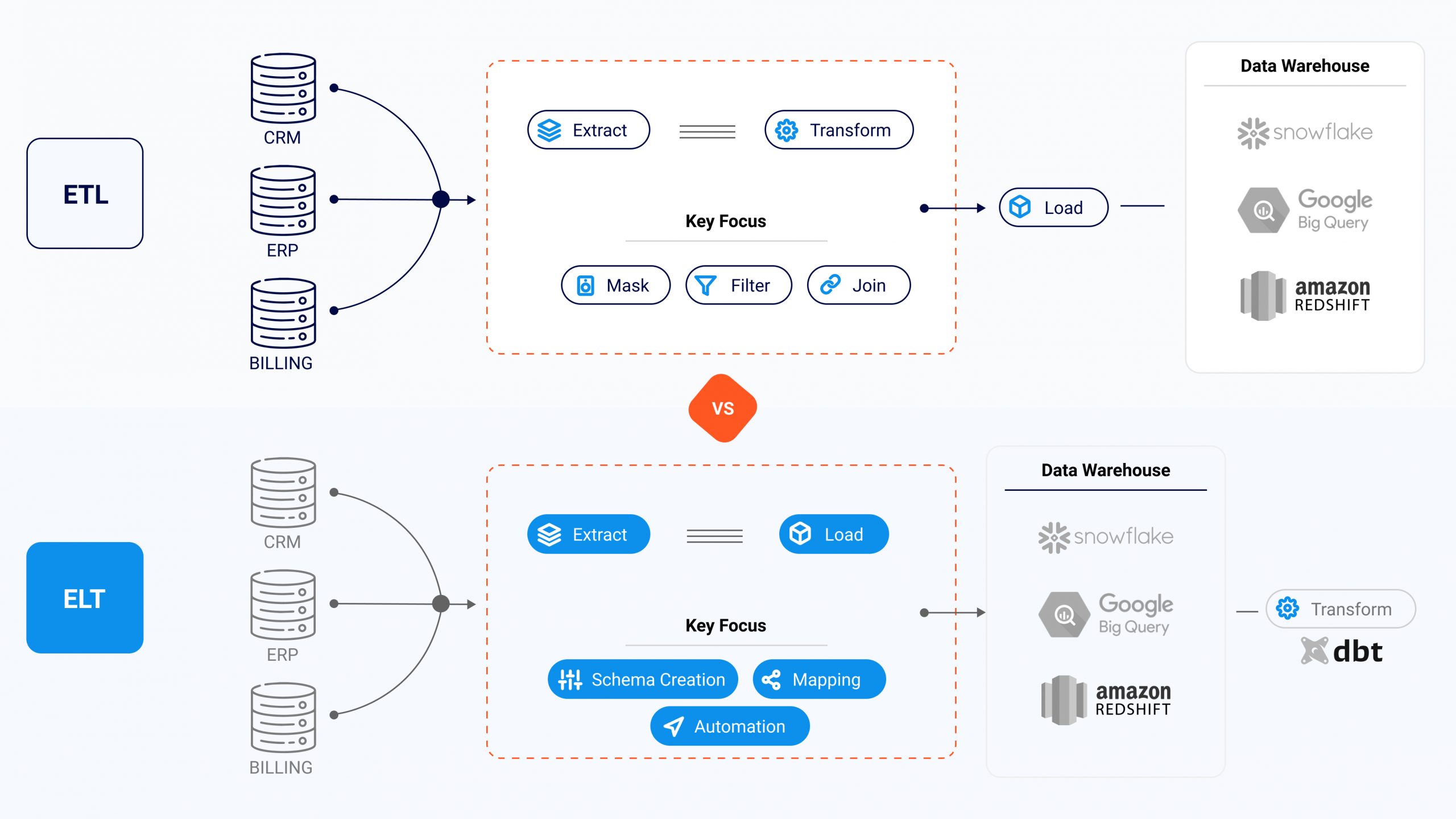
ETL vs ELT.
What We Deliver.
CapeStart’s data engineering services help eliminate data silos caused by legacy systems, allowing your organization to more easily ingest, integrate, and load data from a range of sources and use it to drive first-class business intelligence (BI).
Reliable and Scalable Data Pipelines.
- Automate data ingestion of structured and unstructured data from internal or external sources via batch or real-time processing
- Build extract/transform/load (ETL) or extract/load/transform (ELT) pipelines to ingest and integrate massive amounts of data from multiple sources faster and more efficiently
- Configure deployment pipelines using Jenkins, CircleCI, Github Actions, Azure DevOps, and AWS CodePipeline
- Empower business users with lightning fast query processing times and more available, higher quality data
- Enable advanced and scalable AI/ML models and MLOps practices
- Pipeline versioning and workflow orchestration using Kubeflow, Airflow and other tools
Cloud Data Warehouse Migration.
- Seamless on-premises-to-cloud or C2C database migrations to a modern cloud data warehouse such as Azure, AWS, Google Cloud, and DigitalOcean – secure, at scale, and fully compliant with HIPAA and SOC 2 Type II
- Improve business agility with flexible, secure, and highly available cloud architecture
- Capitalize on cloud-native tools, technologies, and automation
- Optimize total cost of ownership (TCO), minimize CapEx, and maximize compute and storage performance with a scalable, secure, and reliable cloud data warehouse
DataOps and Data Management.
- Enable continuous integration and continuous development (CI/CD) for data pipelines through infrastructure-as-code (IaC) deployments
- Lean on proven DataOps methodologies for seamless integration, deployment, monitoring, testing, and performance tuning
- Optimize data quality, cleanliness, and traceability with end-to-end data governance
- 24/7 global operational support ensures high uptime, near-instant response times and lower platform administration costs
MLOps.
- Continuous input stream data collection, data ingestion and preparation for downstream ML applications, and data analysis/curation
- Data labeling and annotation, data validation, and data preparation including splitting and versioning
- ML system validation and deployment to production, ML model evaluation, and model training
What’s the CapeStart Difference?
We help enterprises just like yours implement and automate robust and scalable data pipelines, cloud infrastructure, and data management workflows.

Customized Data Engineering Solutions
Your dedicated data engineering team analyzes your requirements and develops a robust execution plan to fit any size budget.

A Wealth of Technical Experience
Our dedicated, in-house teams are fluent in a wide range of data engineering technologies, including Pub/Sub, Dataflow, Dataproc, and Dataprep.

Proven Methodologies
Our iterative, business outcome-driven approach and field tested methodologies help maximize ROI and minimize uncertainty.

We’ve Seen Every Use Case
Years of experience migrating legacy on-premises systems to public, private, hybrid or multi-cloud environments.